Dubbo loadbalance(4) - ConsistentHash ConsistentHashLoadBalance 本文我们讨论dubbo提供的负载均衡策略:一致性哈希负载均衡。本文没有特殊标注的话,均为2.7.4.1 版本
哈希算法 在介绍一致性哈希算法之前,我们先看看哈希算法,哈希算法解决了什么问题,带来了什么问题。
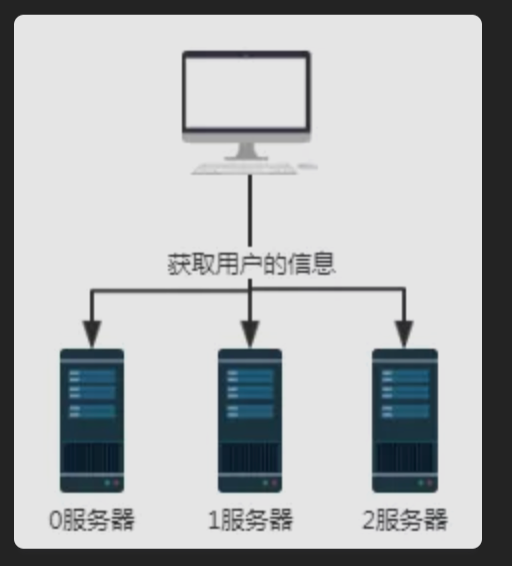
如上图所示,假设我们0、1、2服务器都存储部分用户信息,那么如果我们需要获取用户信息时,不知道用户信息存储在哪一台服务上,所以需要分别查询0,1,2号服务器。这样获取数据的效率是极低的。
对于上面的场景,我们引入哈希算法之后。
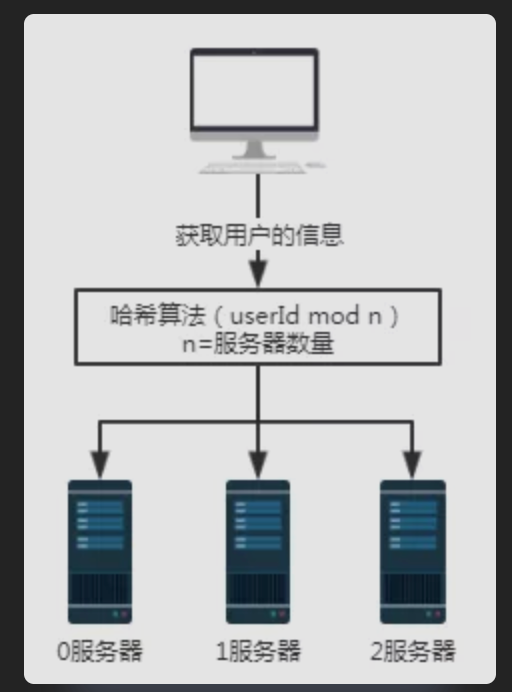
我们用户的信息,提前按照指定哈希算法存放。所以取用户信息的时候,按照哈希算法来取即可。
假设我们要查询用户号为100的用户信息,经过某个哈希算法,比如这里的userId mod n,即100 mod 3结果为1。所以用户号100的这个请求最终会被1号服务器接收并处理。
这样解决了我们查询无效的问题,但是这样的方案带来了什么问题呢?
当我们服务器扩容或者减少的时候,每个用户都要重新计算mod,一定会涉及到大量数据迁移。
对于上诉哈希算法其优点是简单易用,大多数分库分表规则就采取的这种方式。一般是提前根据数据量,预先估算好分区数。
其缺点是由于扩容或收缩节点导致节点数量变化时,节点的映射关系需要重新计算,会导致数据进行迁移。所以扩容时通常采用翻倍扩容,避免数据映射全部被打乱,导致全量迁移的情况,这样只会发生50%的数据迁移 。
假设这是一个缓存服务,数据的迁移会导致在迁移的时间段内,有缓存是失效的。
一致性哈希算法 为了解决哈希算法带来的数据迁移问题,一致性哈希算法应运而生。
一致性哈希算法在1997年由麻省理工学院提出,是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系 。一致性哈希解决了简单哈希算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的动态伸缩等问题
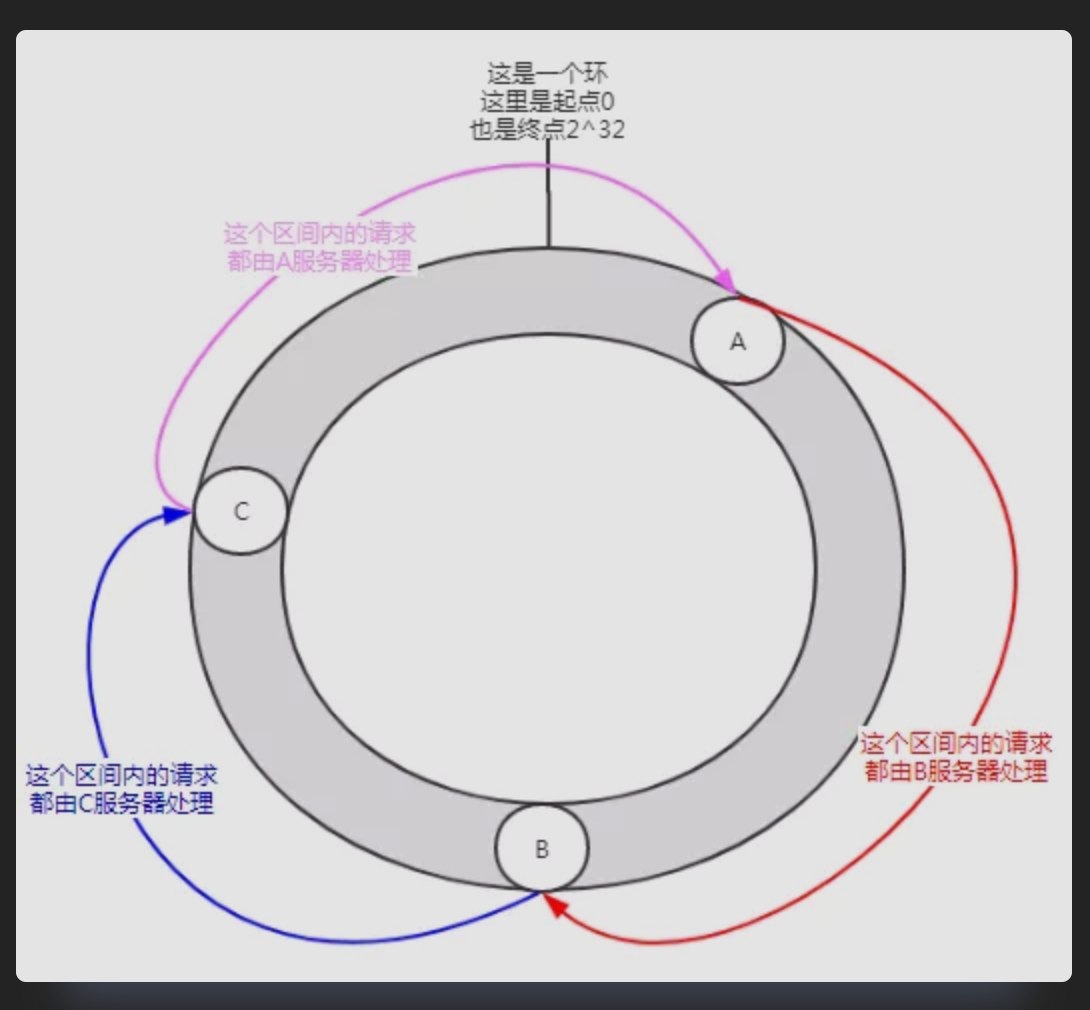
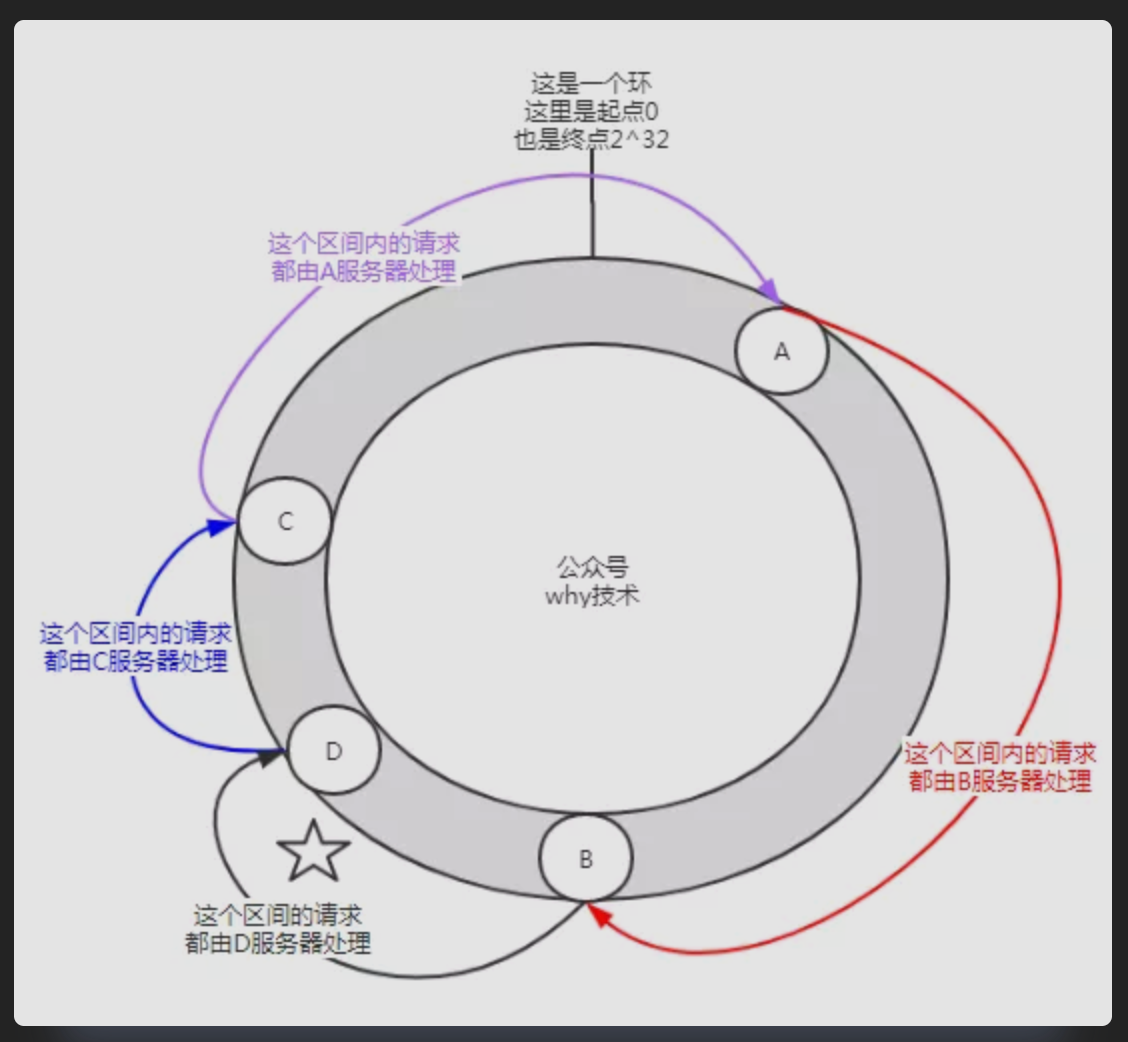
一致性哈希,你可以想象成一个哈希环 ,它由0到2^32-1个点组成。A,B,C分别是三台服务器,每一台的IP加端口经过哈希计算后的值,在哈希环上对应如下:
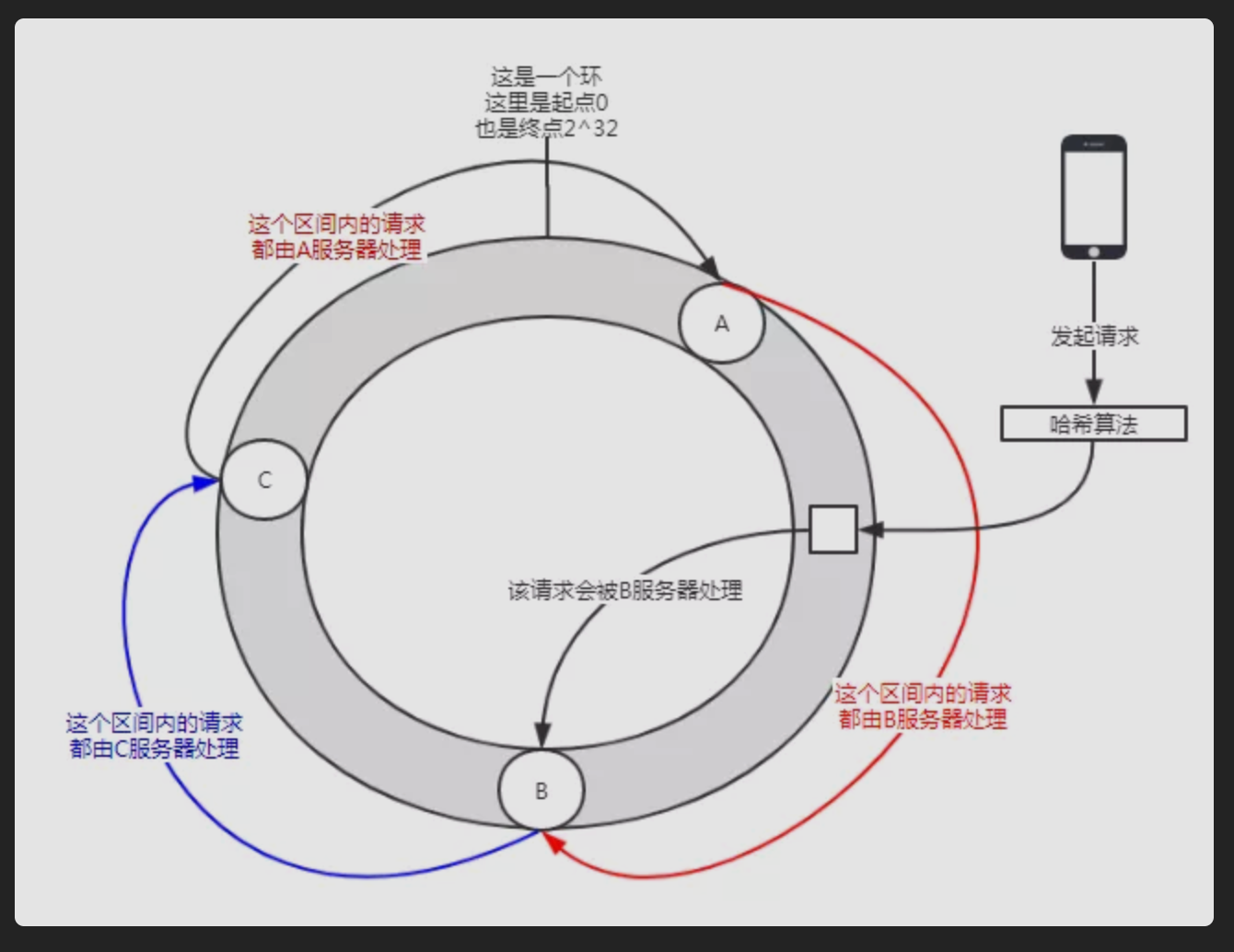
当请求到来时,对请求中的某些参数进行哈希计算后,也会得出一个哈希值,此值在哈希环上也会有对应的位置,这个请求会沿着顺时针的方向,寻找最近的服务器来处理它 ,如下图所示:
一致性哈希就是这么个东西。那它是怎么解决服务器的扩容或收缩导致大量的数据迁移的呢?
看一下当我们使用一致性哈希算法时,加入服务器会发什么事情。
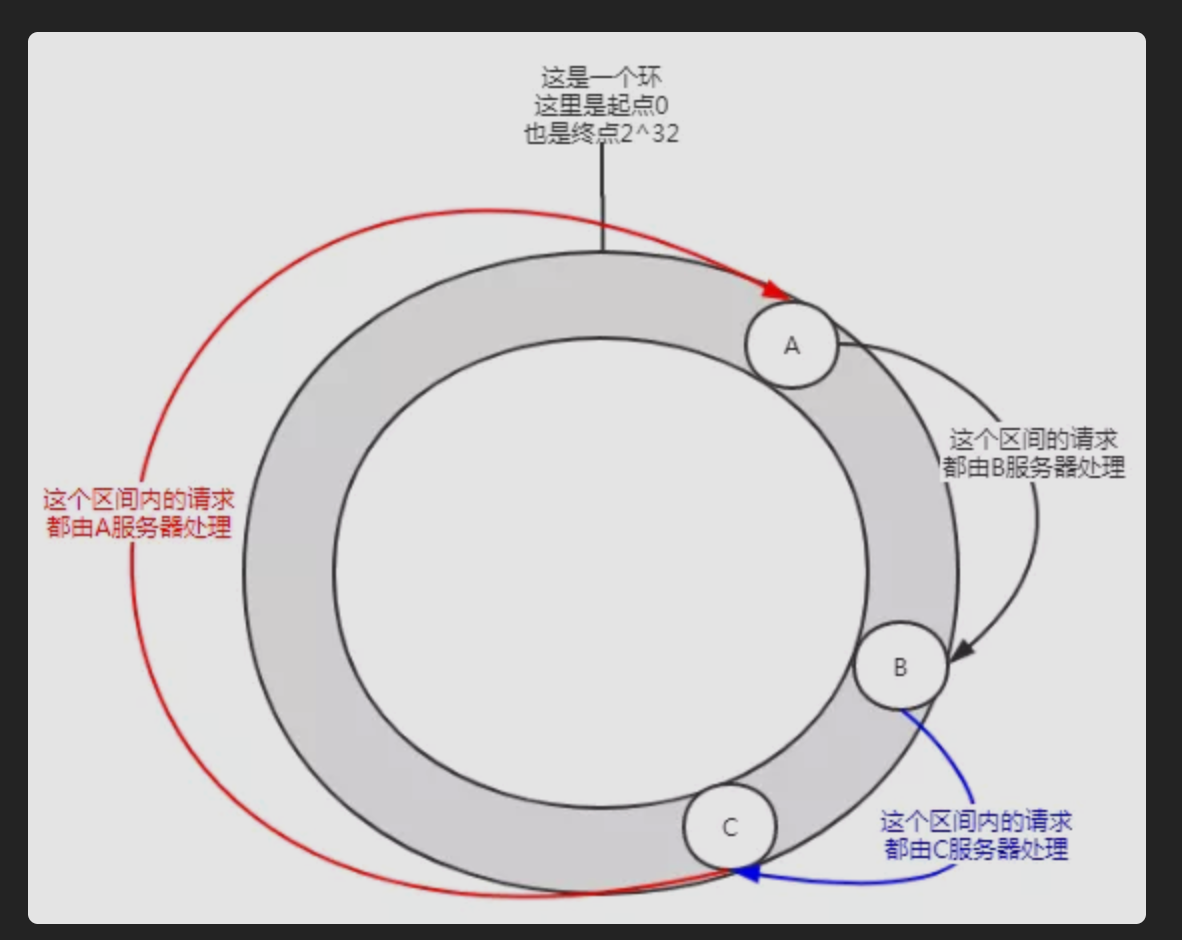
当我们加入一个D服务器后,假设其IP加端口,经过哈希计算后落在了哈希环上图中所示的位置。
这时影响的范围只有图中标注了五角星的区间。这个区间的请求从原来的由C服务器处理变成了由D服务器请求。而D到C,C到A,A到B这个区间的请求没有影响,加入D节点后,A、B服务器是无感知的。
所以,在一致性哈希算法中,如果增加一台服务器,则受影响的区间仅仅是新服务器(D)在哈希环空间中,逆时针方向遇到的第一台服务器(B)之间的区间 ,其它区间(D到C,C到A,A到B)不会受到影响。
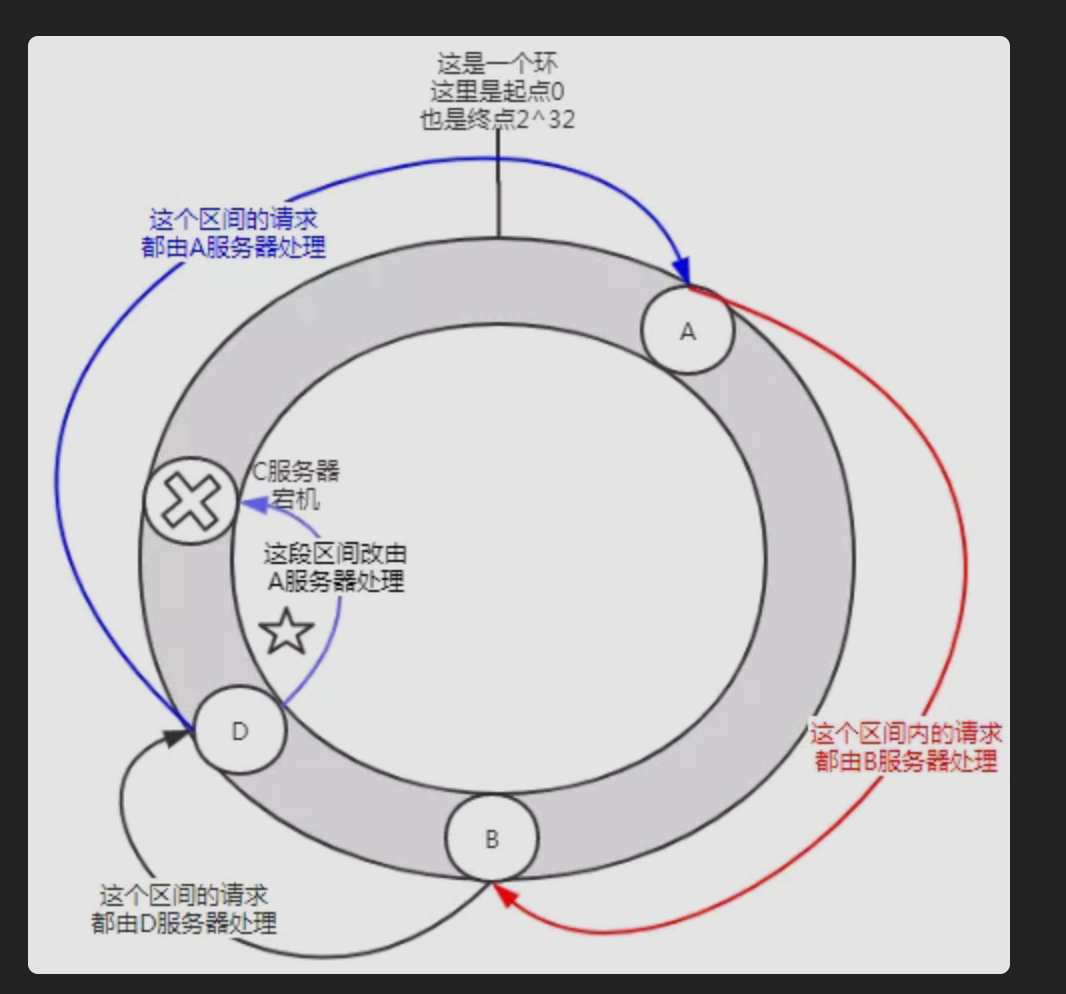
当我们C服务器宕机了,会发生什么呢?
当C服务器宕机后,影响的范围也是图中标注了五角星的区间。C节点宕机后,B、D服务器是无感知的。
所以,在一致性哈希算法中,如果宕机一台服务器,则受影响的区间仅仅是宕机服务器(C)在哈希环空间中,逆时针方向遇到的第一台服务器 (D)之间的区间,其它区间(C到A,A到B,B到D)不会受到影响。
综上所述,在一致性哈希算法中,不管是增加节点,还是宕机节点,受影响的区间仅仅是增加或者宕机服务器在哈希环空间中,逆时针方向遇到的第一台服务器之间的区间,其它区间不会受到影响。
哇,看到这里,你是否觉得一致性哈希算法已经完美了?
并不是的,现实和理想的差距是巨大的。
一致性哈希算法问题,帮我们解决了数据扩缩容的问题。一致性哈希算法给我们带来了什么问题?
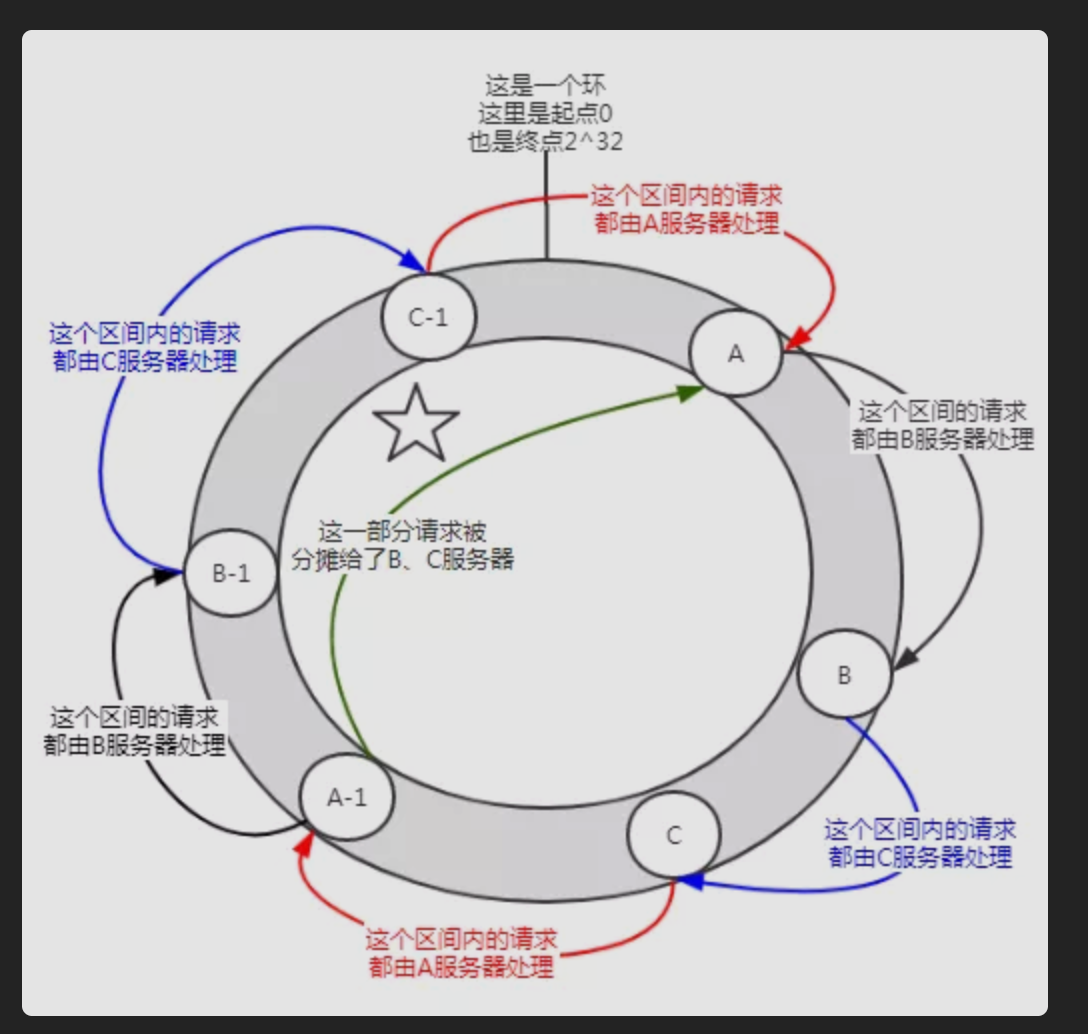
当节点很少的时候可能会出现这样的分布情况,A服务会承担大部分请求。这种情况就叫做数据倾斜 。
怎么解决数据倾斜呢?加入虚拟节点 。
在没有加入虚拟节点之前,A服务器承担了绝大多数的请求。但是假设每个服务器有一个虚拟节点(A-1,B-1,C-1),经过哈希计算后落在了如上图所示的位置。那么A服务器的承担的请求就在一定程度上(图中标注了五角星的部分)分摊给了B-1、C-1虚拟节点,实际上就是分摊给了B、C服务器。
在我们了解完一致性哈希算法的演进之后,我们来看看dubbo是如何落地使用的。
一致性哈希算法在dubbo中的应用 我们在第一篇介绍:最小活跃数负载均衡策略的时候,知道dubbo中负载均衡的实现是通过com.alibaba.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance#doSelect该抽象方法实现。
com.alibaba.dubbo.rpc.cluster.loadbalance.ConsistentHashLoadBalance
是我们要研究的核心累,但是因为一致性哈希实现类比较复杂,并且为了便于我们debug。还有dubbo给我们提供了这样的能力。LoadBalance是一个SPI接口。
我们定义我们一致性哈希负载均衡实现类,增加一些日志输出方便debug。
package com.noah.dubbo.loadbalance;import org.apache.dubbo.common.URL;import org.apache.dubbo.rpc.Invocation;import org.apache.dubbo.rpc.Invoker;import org.apache.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance;import org.apache.dubbo.rpc.support.RpcUtils;import org.springframework.stereotype.Component;import java.nio.charset.StandardCharsets;import java.security.MessageDigest;import java.security.NoSuchAlgorithmException;import java.util.List;import java.util.Map;import java.util.TreeMap;import java.util.concurrent.ConcurrentHashMap;import java.util.concurrent.ConcurrentMap;import static org.apache.dubbo.common.constants.CommonConstants.COMMA_SPLIT_PATTERN;@Component public class NoahConsistentHashLoadBalance extends AbstractLoadBalance { public static final String NAME = "noahconsistenthash" ; public static final String HASH_NODES = "hash.nodes" ; public static final String HASH_ARGUMENTS = "hash.arguments" ; private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap <String, ConsistentHashSelector<?>>(); @SuppressWarnings("unchecked") @Override protected <T> Invoker<T> doSelect (List<Invoker<T>> invokers, URL url, Invocation invocation) { System.out.println("welcome to noahconsistenthash" ); String methodName = RpcUtils.getMethodName(invocation); String key = invokers.get(0 ).getUrl().getServiceKey() + "." + methodName; System.out.println("从selectors中获取value的key=" + key); int invokersHashCode = invokers.hashCode(); ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key); if (selector == null || selector.identityHashCode != invokersHashCode) { System.out.println("是新的invokers:" + invokersHashCode + ",原:" + (selector == null ? "null" : selector.identityHashCode)); selectors.put(key, new ConsistentHashSelector <T>(invokers, methodName, invokersHashCode)); selector = (ConsistentHashSelector<T>) selectors.get(key); System.out.println("哈希环构建完成,详情如下:" ); for (Map.Entry<Long, Invoker<T>> entry : selector.virtualInvokers.entrySet()) { System.out.println("key(哈希值=)" + entry.getKey() + ",value(虚拟节点)=" + entry.getValue()); } } return selector.select(invocation); } private static final class ConsistentHashSelector <T> { private final TreeMap<Long, Invoker<T>> virtualInvokers; private final int replicaNumber; private final int identityHashCode; private final int [] argumentIndex; ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) { this .virtualInvokers = new TreeMap <Long, Invoker<T>>(); this .identityHashCode = identityHashCode; URL url = invokers.get(0 ).getUrl(); this .replicaNumber = url.getMethodParameter(methodName, HASH_NODES, 160 ); String[] index = COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, HASH_ARGUMENTS, "0" )); argumentIndex = new int [index.length]; for (int i = 0 ; i < index.length; i++) { argumentIndex[i] = Integer.parseInt(index[i]); } for (Invoker<T> invoker : invokers) { String address = invoker.getUrl().getAddress(); for (int i = 0 ; i < replicaNumber / 4 ; i++) { byte [] digest = md5(address + i); for (int h = 0 ; h < 4 ; h++) { long m = hash(digest, h); virtualInvokers.put(m, invoker); } } } } public Invoker<T> select (Invocation invocation) { String key = toKey(invocation.getArguments()); byte [] digest = md5(key); return selectForKey(hash(digest, 0 )); } private String toKey (Object[] args) { StringBuilder buf = new StringBuilder (); for (int i : argumentIndex) { if (i >= 0 && i < args.length) { buf.append(args[i]); } } return buf.toString(); } private Invoker<T> selectForKey (long hash) { Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash); if (entry == null ) { entry = virtualInvokers.firstEntry(); } return entry.getValue(); } private long hash (byte [] digest, int number) { return (((long ) (digest[3 + number * 4 ] & 0xFF ) << 24 ) | ((long ) (digest[2 + number * 4 ] & 0xFF ) << 16 ) | ((long ) (digest[1 + number * 4 ] & 0xFF ) << 8 ) | (digest[number * 4 ] & 0xFF )) & 0xFFFFFFFFL ; } private byte [] md5(String value) { MessageDigest md5; try { md5 = MessageDigest.getInstance("MD5" ); } catch (NoSuchAlgorithmException e) { throw new IllegalStateException (e.getMessage(), e); } md5.reset(); byte [] bytes = value.getBytes(StandardCharsets.UTF_8); md5.update(bytes); return md5.digest(); } } }
上面的代码,我增加了注释和输入语句,方便你理解代码的意思。体会源码的魅力。
一致性哈希的应用场景 当大家谈到一致性哈希算法的时候,首先的第一印象应该是在缓存场景下的使用 ,因为在一个优秀的哈希算法加持下,其上下线节点对整体数据的影响(迁移)都是比较友好的。
但是想一下为什么Dubbo在负载均衡策略里面提供了基于一致性哈希的负载均衡策略?它的实际使用场景是什么?
我最开始也想不明白。我想的是在Dubbo的场景下,假设需求是想要一个用户的请求一直让一台服务器处理,那我们可以采用一致性哈希负载均衡策略,把用户号进行哈希计算,可以实现这样的需求。但是这样的需求未免有点太牵强了,适用场景略小。
如果需求是需要保证某一类请求必须顺序处理呢?
如果你用其他负载均衡策略,请求分发到了不同的机器上去,就很难保证请求的顺序处理了。
比如A,B请求要求顺序处理,现在A请求先发送,被负载到了A服务器上,B请求后发送,被负载到了B服务器上。
而B服务器由于性能好或者当前没有其他请求或者其他原因极有可能在A服务器还在处理A请求之前就把B请求处理完成了。这样不符合我们的要求。
这时,一致性哈希负载均衡策略就上场了,它帮我们保证了某一类请求都发送到固定的机器上去执行。比如把同一个用户的请求发送到同一台机器上去执行,就意味着把某一类请求发送到同一台机器上去执行。所以我们只需要在该机器上运行的程序中保证顺序执行就行了,比如你加一个队列。
一致性哈希算法+队列,可以实现顺序处理的需求。